Building an AI-powered product is a multi-stage process that begins with defining a real business need and ends with a usable, scalable solution that delivers consistent value. Whether you’re planning a smart assistant, a recommendation engine, or a predictive analytics tool, the path from idea to deployment requires careful planning, the right tech stack, and a deep understanding of both your users and your data.
In this guide, we’ll walk through the complete AI product development lifecycle — from early-stage validation to architecture, deployment, and beyond. If you’re still unsure whether your business even needs to develop custom software, or whether your infrastructure can support AI integrations instead, you may want to start here with our AI integration strategy guide.
But if you’re ready to build, let’s get started.

Validating the Idea: Is There Real Demand
Before touching any code or drafting user flows, it’s critical to validate whether your AI product idea actually solves a meaningful problem and whether it’s technically feasible.
Here’s how to do it right:
- Define the core value proposition: What is the measurable outcome you’re pursuing? Are you replacing manual effort, reducing decision latency, personalizing user experience, or something else entirely? Not every problem needs AI, and clarity here will help you avoid bloat and scope creep.
- Assess data readiness and access: Does your organization have access to the required data? Is it structured, labeled, or buried in unstructured PDFs and legacy systems? Many AI-powered projects stall because the input data doesn’t match the ambition. If you’re not ready to build yet, consider preparing your systems for AI with our AI Integration Services.
- Determine model suitability and constraints: Will general-purpose LLMs like GPT, Claude, or Gemini suffice? Do you need a specialized vision model or real-time response? Does your use case involve compliance-heavy environments like healthcare or finance?
- Talk to users and stakeholders: Will they trust and use this tool? How will it fit into their existing workflows?
If that feels overwhelming, you can also delegate this task to companies with extensive expertise in completing a full-fledged discovery process, and saving time and money for the clients even before the development starts.
Defining the Scope and Use Cases
Once the idea is validated, the next step is shaping it into something buildable. Defining the scope is where many AI projects either gain momentum or get bogged down by unclear expectations.
1. Clarify what the product should do and not do
List specific tasks the AI needs to perform. Is it summarizing documents? Generating customer support responses? Classifying emails by intent? Define outputs, formats, triggers, and acceptable accuracy thresholds. Be just as clear about what’s out of scope to keep development focused.
2. Break the system down into modules
Many AI products aren’t monoliths. They rely on orchestration between components: user input parsing, inference engine, data preprocessing, content moderation, and output rendering. Thinking in terms of modular units makes it easier to prototype, test, and upgrade over time, particularly if you’re using a modular AI development approach tailored to enterprise environments.
3. Map out user flows and interactions
Whether it’s a chatbot, dashboard, or a background automation system, define how users will interact with the AI. Where does the model plug into the UX? Will the AI provide suggestions, act autonomously, or wait for confirmation? Understanding these user flows helps align product features with actual user needs and technical capabilities.
4. Identify dependencies and integration points
What existing software will the AI product rely on? Are you building into a CRM, an internal dashboard, or a third-party API? Knowing your tech stack’s flexibility (or rigidity) early helps avoid over-engineering and surprises during deployment.
Building the Dataset and Preprocessing Pipeline
Regardless of which model you choose, it will need data to perform what you want it to. A dataset is what your model will learn from, and then help you and your business thrive.
What data is needed, and how to clean it
Before writing a single line of code, you need to decide what kind of data your AI solution will learn from. Are you building a customer support tool? Then historical chats or emails might be your base. Developing an AI tutor? You’ll need structured learning materials, exam formats, or lesson plans.
But raw data is messy. Typos, formatting inconsistencies, and irrelevant content all create noise. Data scientists apply a process called preprocessing to clean it up: normalizing formats, removing duplicates, and tagging content where needed.
Think of it as a library. It contains everything you need, but it would be much easier to find something when it’s located on its dedicated shelf, as opposed to just scattered across the place and mislabeled. That’s the cleanup that preprocessing does.

Custom vs. off-the-shelf datasets
In some cases, you can buy a dataset. There are curated, licensed datasets available for training chatbots, sentiment analysis engines, and other generic models. This can work well if you’re solving a problem many others have solved before.
But if your solution is domain-specific, there may not be a dataset for that yet. And there may never be one made, simply because of how niche or industry-specific your business and needs are.
Let’s say you’re building an AI for legal compliance, mental health diagnostics, or equipment failure detection. There’s a high probability that an off-the-shelf dataset won’t cut it. You’ll need to build your own, sourcing proprietary company data or publicly available domain materials, and often partnering with domain experts to label and verify it.
This is where data privacy, ownership, and compliance come into play. If you’re training on sensitive healthcare data, for example, anonymization and regulatory controls like HIPAA or GDPR are non-negotiable.
Choosing the Right Tech Stack
Picking the right technologies to build your AI product directly impacts cost, scalability, security, and time-to-market. Business leaders don’t need to know how every tool works under the hood, but it’s crucial to understand what each piece of the stack enables and how it aligns with your goals.
Frameworks and libraries
The foundation of any AI solution lies in the frameworks it’s built on. These are the engines that train and run your models.
- TensorFlow and PyTorch are the industry leaders for deep learning development. They power everything from image recognition to advanced language models.
- For projects using large language models (LLMs), tools like LangChain, LlamaIndex, or Haystack help structure your workflows, especially if you’re building AI chatbots or retrieval-augmented generation (RAG) solutions.
- Frameworks like FastAPI or Flask are used to deploy AI models as usable services and APIs, letting them connect with your other systems.
Choosing the right frameworks early on determines not only what your model can do, but also how easily it can grow or change later.
Hosting and deployment
Where your model runs and how accessible it is matter as much as the model itself.
- Cloud platforms like AWS, Google Cloud, or Azure offer scalable infrastructure and managed services for AI, including data storage, GPU access, and deployment pipelines.
- For companies handling highly sensitive data (healthcare, finance, education with student personal info), on-premise deployment or private cloud setups may be required to maintain full control over infrastructure, residency, and compliance.
Integration with existing platforms
No AI solution exists in a vacuum. Whether it’s integrating with your CRM, ERP, EHR, LMS, or any other custom platform, your AI tools must fit into your current environment.
This is where middleware, custom APIs, or endpoint wrapping come into play, ensuring your AI model doesn’t become a standalone experiment but a functioning part of your operational ecosystem.
Model Development and Fine-Tuning
Once your data and tech stack are in place, the next step is building (or adapting) the model itself. This is where your AI solution learns how to perform the task you want it to do, from understanding language to detecting patterns in behavior, documents, or images.
Custom model training: when and why it matters
Off-the-shelf models like GPT, Claude, or Gemini are powerful, but they’re generalists. If your use case involves industry-specific language, rules, or workflows, custom training ensures your AI speaks your language, literally.
We fine-tune models to:
- Improve domain relevance (legal, medical, or industrial contexts)
- Align output with business-specific terminology and expectations
- Reduce hallucinations and ensure consistency over time
Custom training isn’t technically necessary, but if you want AI to work within the context of your business, there’s no best way to achieve this.
Transfer learning vs. training from scratch
AI doesn’t have to start from zero. With transfer learning, your model starts with a pre-trained base (like GPT or BERT) and is fine-tuned on your specific data. This saves time, money, and resources.
Training from scratch is more expensive and typically only justified when:
- No suitable pretrained model exists
- Your data is highly sensitive or proprietary
- You need full control over every aspect of the model’s behavior
Here’s an example from real life. We took a pre-trained GPT and modified it to contain the data that our client needed for the business. As a result, we built a ChatGPT-based study assistant that would respond to specific academic questions with in-depth, sharp knowledge without hallucinating.
Evaluation metrics and benchmarks
Even a well-trained model needs to be evaluated. We use metrics like accuracy, precision, recall, F1 score, and BLEU score (for language models) to measure how well the AI is performing.
Evaluation tells you:
- Whether the model is business-ready
- Where it’s likely to make mistakes
- How performance improves with more data or new iterations
There’s no magic pill in this case. Benchmarks and preliminary evaluations have to be followed up by constant ongoing monitoring to avoid drift over time and catch the patterns of change in either the model itself or the way it affects the business.
Compliance and Ethical Considerations
In sectors that handle personal information and other sensitive data, the regulatory context is always evolving, and building a product that ignores this reality is a fast track to legal exposure or loss of user trust.
Compliance influences how you collect data, what your models are allowed to predict, and how results are delivered to users. From GDPR-mandated transparency to HIPAA-governed medical records handling, each domain brings its own expectations.
This is where explainability, auditability, and human oversight come in. Whether your system is offering treatment suggestions or analyzing academic performance, stakeholders will want to understand how decisions were made and who is responsible.
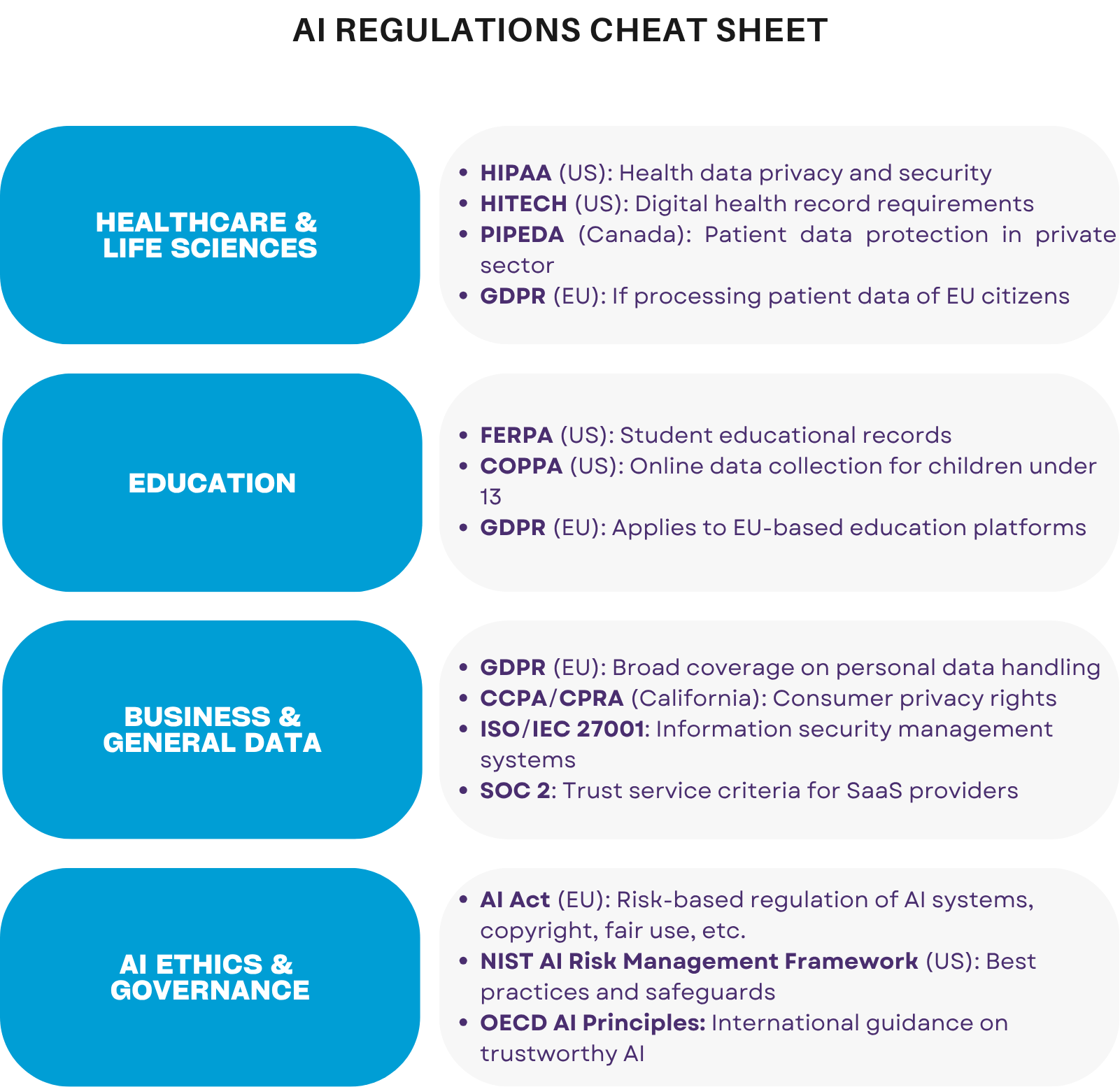
When building compliant AI systems, here are some of the most relevant regulatory frameworks to consider:
- GDPR (General Data Protection Regulation)
Mandates user data privacy, transparency, and the right to explanation for automated decision-making in the EU and beyond. - HIPAA (Health Insurance Portability and Accountability Act)
Governs the use and protection of personal health information (PHI) in U.S. healthcare environments. - FERPA (Family Educational Rights and Privacy Act)
Protects student education records in institutions receiving U.S. federal funding, essential for EdTech solutions. - PIPEDA (Personal Information Protection and Electronic Documents Act)
Canada’s federal data privacy law, applicable to commercial use of personal data. - ISO/IEC 27001
International standard for managing information security, often used to demonstrate enterprise-grade risk and security posture. - HITECH Act
U.S. law that supports the enforcement of HIPAA, with a strong focus on digital health records and security.
These considerations and consequent planning have to come very early in the design and development process to avoid costly remakes. Consult with the cheat sheet below to see more regulations and relevant standards to keep track of when developing an AI-powered software solution.
The Takeaway
Building an AI product is never just about code. It’s a puzzle made of data sourcing, regulatory awareness, scalable infrastructure, user needs, and constant iteration. Even with the right talent, it’s easy to underestimate how much time and coordination it really takes to get it right.
That’s why we always recommend starting with a real problem, not a feature wishlist. If your business pain points are clear, you’ll have a much easier time scoping the solution, choosing the right technology, and validating early whether AI is even the right tool for the job.
If you’re not sure whether to build from scratch or integrate existing AI into your product, we’ve covered that decision-making process in our AI integration guide. It’s a great place to begin.
Need a partner who knows how to navigate AI architecture, product planning, and deployment in real-world environments?
Explore our AI Development Services, or reach out for a no-pressure consultation.