The more we study and build our businesses, the more we feel like organizations are inundated with unstructured data like documents, emails, scans, and PDFs. Analysts estimate that a staggering 80–90% of enterprise data remains unleveraged simply because it lacks structure. Meanwhile, the Intelligent Document Processing (IDP) market is expected to surge from around $3 billion in 2025 to nearly $10 billion by 2029. These trends reflect a fundamental shift in how businesses manage and extract value from their document workflows.
Traditional Optical Character Recognition (OCR) systems excel at converting printed words into text, but they don’t understand context. AI-enhanced computer vision, natural language processing (NLP), and machine learning (ML) turn that text into actionable insight, capturing form layouts, extracting key-value pairs, and routing documents automatically. The result? Sharper accuracy, greater productivity, significant cost savings, and enhanced scalability and compliance
In this article, we’ll explore how computer vision and AI combine to form end-to-end document processing pipelines. We’ll break down the technology, highlight real-world use cases, share insights on implementation, and help you understand how to translate unstructured data into business value.
What Is AI‑Powered Document Processing?
AI‑powered document processing, or Intelligent Document Processing (IDP), is the evolution beyond classic OCR. At its core, IDP synergizes computer vision, optical character recognition (OCR), natural language processing (NLP), and machine learning (ML) to automatically classify, extract, validate, and integrate data from diverse document types.
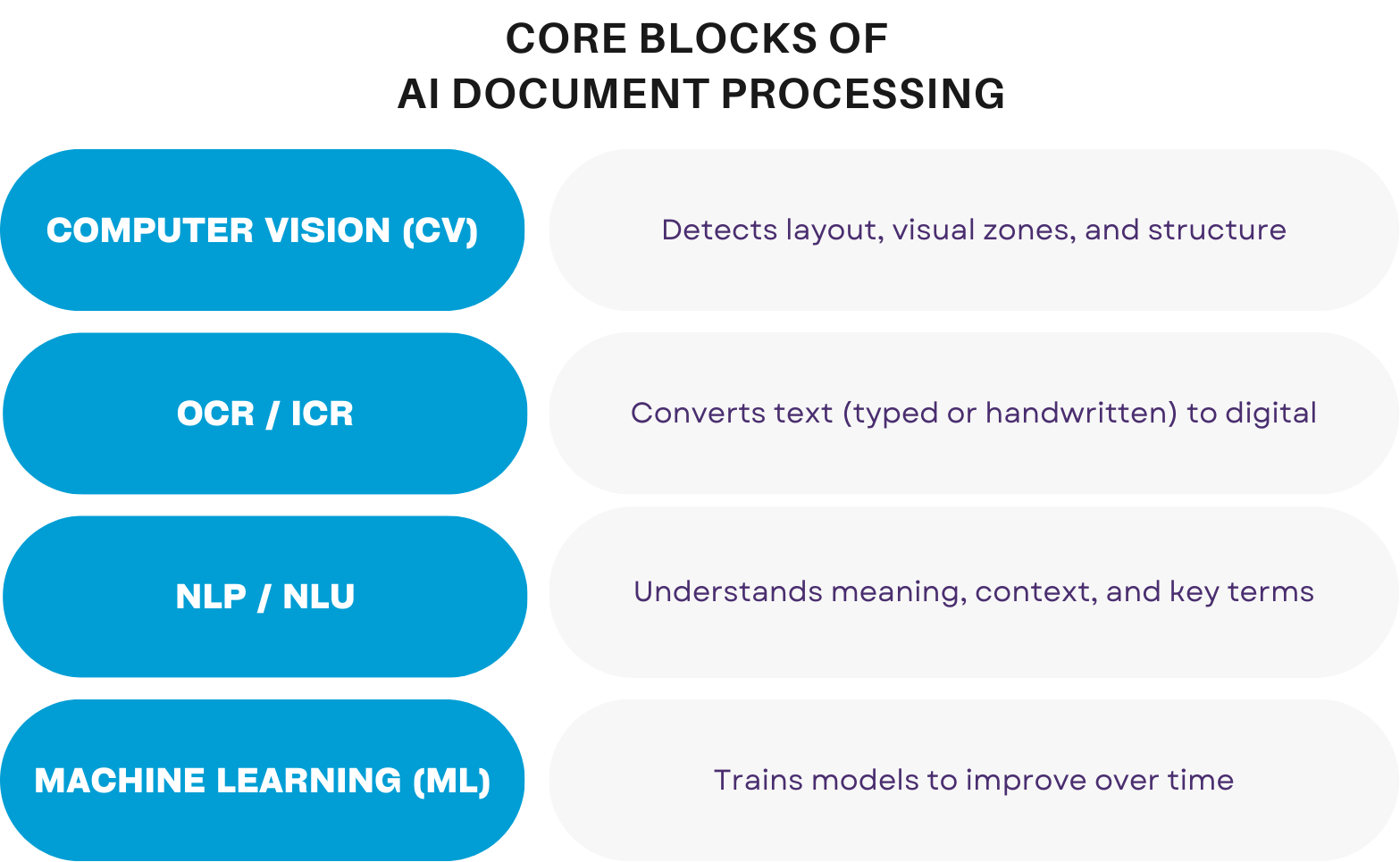
- Computer Vision (CV) allows systems to detect document structure, tables, signatures, and handwritten text by analyzing visual elements of scanned or photographed documents.
- Optical Character Recognition (OCR/ICR) converts printed or handwritten characters into machine-readable text, forming the base for further understanding.
- Natural Language Processing (NLP) extracts semantics: identifying entities, interpreting context, and enabling sentiment or intent detection where applicable.
- Machine Learning (ML) fuels adaptive learning, enabling pipelines to improve classification and extraction performance across varied layouts and languages.
This integrated stack ensures IDP systems can:
- Classify documents (differentiating invoices, contracts, receipts
- Extract key-value pairs (dates, amounts, names) with semantic accuracy
- Validate data against rules or external systems (DB lookup)
- Route/Integrate the structured data into ERP, CRM, or analytics systems .
In contrast to OCR-only workflows, AI-powered pipelines reduce manual effort, increase straight-through processing (STP), and enable actionable automation, not just digitization.
Real‑World Applications Across Industries
AI-powered document processing is already shaping operations across sectors by automating data ingestion and decision-making from diverse document formats. Here are industry-leading use cases:
Healthcare
- Medical billing and electronic health record (EHR) ingestion: Automates claim submissions by extracting data from invoices, prescriptions, and lab reports. Contributes to the semantic enrichment of EHRs.
- Clinical document analytics: Uses NLP on scanned doctors’ notes and reports to tag entities, symptoms, and treatment plans, speeding up research and reporting pipelines.
Banking & Finance
- Loan processing & KYC onboarding: Automates the extraction of client data from application forms, credit reports, IDs, and bank statements. Enhances fraud detection by spotting anomalies in documents and speeding up approvals.
- Invoice and statement reconciliation: Accelerates bookkeeping and audit compliance by auto-capturing invoice line items and matching them against purchase records.
Insurance
- Claims intake and policy workflow: Scans claim forms, loss details, receipts, and adjuster notes with high accuracy. Improves fraud detection and claim lifecycle time.
- Underwriting and regulatory compliance: Extracts and validates data from medical records, policy applications, and regulatory forms for due diligence.
Legal & Contract Management
- Contract review and key clause extraction: Identifies parties, dates, obligations, and renewal terms. Accelerates due diligence and mitigates risk.
- Regulatory document compliance: Processes filings, audit documentation, and compliance kits efficiently, ensuring accurate recordkeeping.
Logistics & Supply Chain
- Waybills, Proof of Delivery (PODs), customs forms: Extracts shipment dates, stock-keeping units (SKUs), and delivery details, even from poor-quality photos. Improves traceability and fulfillment speed.
- Inventory & delivery audit: Detects signatures, stamps, and condition photos to auto-verify proof of delivery.

How Computer Vision Enhances Document Understanding
Modern document workflows rely heavily on computer vision to transform flat images into intelligent, structured outputs. At the core are techniques in document layout analysis, which detect geometric elements like text zones, tables, images, and logical blocks such as headers and footers. This segmentation helps guide OCR and downstream AI models by distinguishing meaningful regions from noise.
Recent advances have adopted transformer-based and object-detection architectures (like YOLOv5, Vision Grid Transformers, and hybrid models), allowing systems to identify document components with exceptional accuracy.
For example, a 2023 study using YOLOv5 achieved an F1‑score of 0.939 and precision/recall near 0.91/0.97 for multi-element layout detection.
In simpler terms, this means the AI was able to detect and label things like tables, text blocks, and images on a document page with more than 90% accuracy, and it missed very few elements. In practical use, this translates to cleaner data extraction and fewer errors when processing complex layouts, even when the documents vary in format or quality.
Another recent work highlights open-source models for handwritten signature detection, achieving strong precision–recall performance (~95% and ~90%) and suitable deployment via Triton Inference Server.
Taken together, these innovations show that computer vision does more than just “see” text; it understands document structure visually, enabling reliable extraction of structured information even in noisy real-world scenarios. Compared to template-based or OCR-only workflows, modern CV pipelines deliver:
- Layout-adaptive processing — models adjust to varied formats without per-template rules.
- Visual object detection — stamps, tables, logos, graphics, and handwriting are localized before OCR.
- Pre-processing resilience — techniques like deskewing, deblurring, and noise reduction preprocess inputs for better results.
Pipeline Overview: From Raw Document to Structured Data
Modern IDP solutions transform everything from scanned PDFs to mobile photos into structured, business-ready data. Here’s how the process typically flows:
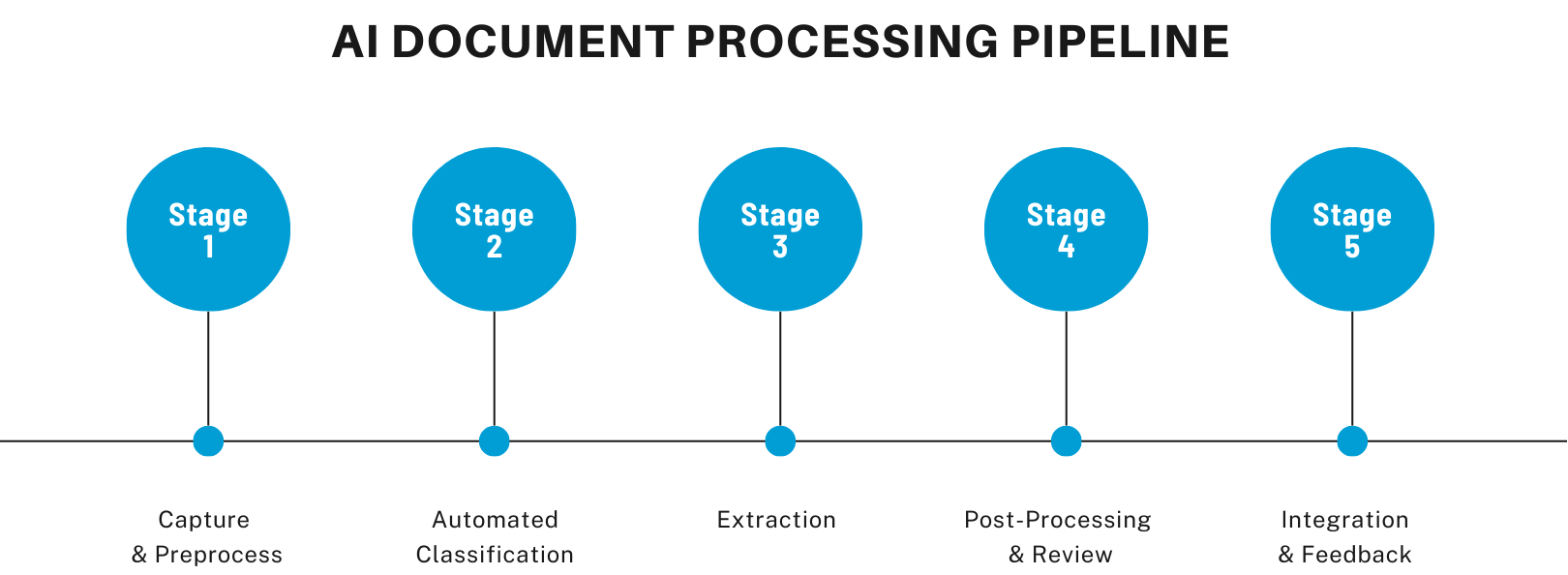
1. Capture & Preprocess:
Documents are ingested via scanners, cameras, or digital uploads. Then, enhancement techniques like deskewing, noise removal, and binarization ensure high OCR accuracy and reduce false positives.
2. Automated Classification:
AI models (CV, NLP) determine document types (invoices, contracts, or lab reports, for example), routing them into appropriate processing workflows. This is vital for batch processing mixed document sets.
3. Extraction:
Using hybrid techniques from OCR/ICR and layout-aware CV, the pipeline extracts key-value pairs, tables, handwriting, and stamps. For instance, Textract’s AnalyzeExpense API pulls line item data from invoices, while table/block detection helps structure results.
4. Post-Processing & Review:
Extracted data is cleansed, validated, and checked against business rules. Items flagged with low confidence are revisited through human-in-the-loop review, balancing automation with accuracy and compliance.
5. Integration & Feedback:
The validated output, typically in JSON/XML, is exported to ERPs, CRMs, data lakes, or RPA systems. Modern pipelines, like AWS-based ones using Step Functions, Lambda, DynamoDB, and Comprehend, include feedback loops where corrected data trains models for improved future accuracy.
At the end of the day, this pipeline ensures that:
- The setup handles thousands of docs per minute with minimal manual input.
- Confidence thresholds and human oversight maintain high-quality data.
- Corrected outputs reinforce model training, improving performance over time.
Choosing the Right Approach: Off-the-Shelf vs. Custom Models
Selecting the correct modeling strategy is crucial for scaling AI document workflows efficiently and effectively. Here’s a quick comparison of off-the-shelf versus custom models:
Off-the-Shelf Models
AWS, Textract, Azure Form Recognizer, and others.
Advantages
- Fast deployment & low initial cost: Set up within days, typically with usage-based pricing or subscriptions, from tens to hundreds per month. Ideal for quick ROI in standardized use cases.
- Proven reliability: Built upon large pre-trained datasets, delivering accurate performance on common document formats.
- Minimal maintenance burden: Vendor handles model updates, scaling, and infrastructure.
Drawbacks
- Limited customization: Difficulty in extracting non-standard fields (GST numbers on invoices).
- Vendor dependency and privacy risks: Data must be sent to cloud services; lock-in can become a long-term cost.
- Performance issues with edge cases: May falter on rotated text, handwritten notes, or uncommon layouts.
- Deployment limitations: Examples like AWS Textract don’t support on-premise options or fine-grained document classification.
Custom Models
Fine-tuned and modified models or built and trained entirely from scratch.
Advantages
- Tailored precision: Performance aligned with organization-specific formats, languages, and data types. Especially valuable for specialized sectors like healthcare and legal.
- Full data control and IP ownership: Enables compliance with stringent privacy standards and ownership of improvements made over time.
- Scalable and flexible architecture: Models designed to adapt and grow, and integrate fully with internal systems like ERP or EHR.
Drawbacks
- Significant upfront investment: Development costs range from tens to hundreds of thousands, including data labeling, model training, infrastructure, and talent.
- Longer time-to-market: Custom projects may take 3–12 months before production deployment.
- Ongoing maintenance requirement: Internal teams or third-party vendors must manage updates, model drift, and system robustness.
- Technical resource dependency: Requires data scientists, ML engineers, and annotators to build and maintain effectively.
Real-life cases often lean towards a hybrid approach, starting with off-the-shelf tools and layering custom logic where needed. This may introduce some gaps or extra maintenance requirements, but if partnered with a team that has proven expertise in developing Computer Vision software, those issues can be mitigated while still saving time and money compared to a full customization approach.
Here’s a quick reference to see the strong and weak points of each approach:

Challenges to Be Aware Of
While AI-powered document systems drive efficiency, organizations must address several real-world obstacles that can impact deployment and outcomes.
1. Data Quality & Variability
Documents often arrive in inconsistent formats. Scan quality varies, images may be skewed or blurry, and layouts can differ significantly. These issues disrupt OCR, layout detection, and downstream NLP models. One report showed manual document workflows carry error rates between 18–40%, errors that poor input quality can exacerbate. Tailored preprocessing, such as deskewing and binarization, is critical but not foolproof.
2. Handwritten & Cursive Text Recognition
Handling handwriting remains a major technical challenge due to its variability and lack of segmentation. Sayre’s paradox describes the mutual dependence of segmentation and recognition in cursive writing. Although recent deep-learning models, including CNN–BLSTM hybrids and transformer-based HTR systems, have improved accuracy, research highlights that performance still struggles with unclear or non‑standard handwriting. Specialized ICR/IWR solutions can help, but they still require significant training and validation.
3. Privacy & Compliance Risks
Processing sensitive documents containing Personal Identifiable Information (PII), medical, or financial data demands strict adherence to regulations like GDPR, HIPAA, and CCPA. Any service that operates in the cloud may introduce risk, and misconfigured or unauthorized data use can and will result in regulatory penalties.
4. Complex Document Formats
Semi-structured or unstructured documents like contracts, emails, or multipart forms contain nested information (tables, stamps, notes) plus implicit semantics. These require layout-aware Computer Vision (CV) combined with Natural Language Processing (NLP) to interpret context, beyond simple OCR. Handling these requires advanced pipelines that accommodate variability and context interpretation.
5. Integration & Scalability Challenges
Enterprises often face integration issues. Connecting IDP systems with legacy ERPs, CRMs, or on-premise document stores introduces complexity. Ensuring that IDP scales to handle thousands of documents per hour without impacting existing workflows requires solid orchestration, infrastructure transparency, and sometimes custom engineering.
6. Human-in-the-Loop Dependency & Change Management
Automating large volumes heightens dependency on fallback mechanisms when model confidence is low. Organizations must establish review queues, retraining loops, and annotation workflows to maintain accuracy, adding operational layers. In practice, these human-in-the-loop processes take time to embed culturally and technically.
What Are The Solutions?
These challenges highlight the nuance and care needed in deploying true AI-powered document pipelines. Effective solutions rely on:
- Robust preprocessing and flexible layout handling
- Specialized models for handwriting and cursive input
- Strong data governance and privacy-aware redaction
- Seamless integration into existing IT ecosystems
- Continuous human–machine collaboration and training
Business Benefits and Impact
AI-powered document processing delivers significant value across multiple business dimensions. Throughout recent years, we have received many proven confirmations of how IDP brings tangible value to organizations of various sizes. Let’s take a look:
Accelerated Processing & Operational Efficiency
Intelligent Document Processing (IDP) can cut document turnaround times by 50–90%. For example, a logistics provider saw processing times drop from seven minutes to under 30 seconds per file, reducing the burden of manual tasks and speeding up response cycles. Cushman & Wakefield automated intake processes and reclaimed 16,000 employee hours, accelerating deal processing by 70% .
Cost Reduction & Labour Savings
IDP results in companies reporting substantial savings in operational expenses after implementing AI document processing. For example, a company saw an 85% drop in processing time and substantial cost avoidance .
Significant ROI and Value Creation
Depending on organization type and business specifics, companies can get substantial value out of IDP. A Forrester TEI study of Amazon’s IDP estimated a 73% ROI and $4.6 million net present value. This includes reductions in errors, scaling potential, and increased throughput.
Improved Data Quality & Compliance
Automation can dramatically cut errors from manual entry and ensure data accuracy. Compliance benefits are clear, document trails are consistent, standardized, and ready for audit. IDP secures structured outputs reliably for regulated sectors.
Productivity Boost & Staff Experience
By shifting employees’ time from administrative tasks to strategic initiatives, IDP enhances job satisfaction and creativity. Harvard Business Review estimates that workers devote ~41% of their time to tasks that are repetitive, boring, and fail to utilize their primary skills. And in many cases, IDP can alleviate the repetitive burden with automation and leave the workers with more time to engage in work that suits their skills.
Scalability & Competitive Agility
IDP scales seamlessly, processing thousands of documents per hour without linear cost increases. Systems remain flexible as data volumes grow, with rapid deployment logic compared to manual methods.
The Takeaway
AI-powered document processing has evolved far beyond basic OCR. With the right blend of computer vision, NLP, and machine learning, businesses can now transform unstructured documents into clean, structured, and actionable data.
Whether you’re automating invoice workflows, reviewing contracts, or processing claims, the impact is consistent: faster cycles, fewer errors, lower costs, and a clear path toward scalable efficiency.
Adopting intelligent document processing is about solving the bottlenecks that slow teams down and hold data hostage in unreadable formats. For many organizations, the gains in speed, compliance, and accuracy speak for themselves.
If you’re considering how to bring AI into your document workflows, it’s worth asking:
What would change if your documents processed themselves?
We help teams move from manual handling to intelligent automation, designed around their data, systems, and goals.
Let’s talk about what that could look like for your business.